


Insight | 01.17.25
Insight | 09.12.22

What could be more dependable than Baseball, Apple Pie and .. Analytics? Mom’s apple pie never disappoints. Baseball, there is always Opening Day next year, when hope springs eternal for participating in the Fall Classic. Okay, it was in doubt in 2020 because billionaires were squabbling with millionaires, being selfish, not For the Love of the Game. But they came around and saved the season. As for analytics and baseball (Sabermetrics), there are terabytes of data that are applied to influence and drive many facets of baseball operations.
Using these tools and relying on lagging indicators has become pervasive in baseball. Our Opening Day blog projected Atlanta winning the division in 2020. This year sources (CBS, The Lines and SI) all predict an Atlanta repeat at 91.5 wins, followed by the Mets, Nationals, Phillies and Marlins at 89, 88, 82 and 71 wins, respectively. You will recall this analysis starts with collecting key data for each player and through proven analytics build a forecast of individual player performance. Using player performance forecasts and building a team roster, the team’s schedule is simulated enough times to achieve projected season performance with the desired level of confidence. Every team is projecting how many wins it will take to get to playoffs and building a team within budget to get there. This process is represented well in a 4 minutes scene in the movie Moneyball.

Oakland, Boston and Tampa Bay pioneered managing by the numbers and continue to manage to their 2021 payrolls of $107M, $77M and $45M respectively. Other teams have been fast followers, applying analytics that have largely leveled the playing field for what were misconceptions in what it takes to win baseball games and what makes a player valuable. Capitalizing on the power of analytics, Major League Baseball has gone beyond roster strategy into additional areas of baseball operations, including:
Businesses are also expanding the use of analytics. There is a thoughtful expansion of analytics use from descriptive/inferential statistics and trailing indicators to supervised/unsupervised learning and natural language processing for:
These result in modern business models which:
All businesses need to evaluate the power of the total analytical tool set in isolating the imperfections in their business models and capitalizing on the imperfections in their competitors’ business models.
How about dependability? Even if it is close, you need to go with Mom’s apple pie, because in the end she is one of the few people who will always love you for who you are. In baseball, the next collective bargaining agreement looms on the horizon and we will need to monitor the owners’ and players’ stewardship of the game. Analytics in baseball has to be applied with judgment. With the right data and a sufficiently large data set it has its appropriate applications. But we need to keep in mind the ’02 Oakland A’s, recent LA Dodger playoff futility (until 2020) and game 6 of the 2020 World Series and taking Blake Snell out of the game. In the postseason, the sample size becomes too small for season-long trends to be significant and it becomes a different ballgame.
In each instance, as in business, historical data and analytics can recommend certain courses of action, but in the moment, there will be outliers and variability that must be considered. Consideration requiring being in the moment and delivering on the leadership opportunity.
Reach out to Yalo for deeper web & marketing analytics expertise. FullStory Analytics and Sentiment Analysis services are just a few of the tools we offer to provide actionable insights to help your business chart the right path forwards.
Insights And News
Insight | 05.11.21
Is Your Social Media Messaging Good Enough?
Does it make a difference what and how you post on social media? Don’t you just need to maintain a presence? Or if you do not have a presence, then how do you know the right message is getting out there to your target audience? In reality, it’s all about emotion, quantity and speed. Your company’s social messages Do make a difference, because business social media is exploding.
The Social Media Explosion
How fast are social networks growing?
Across age groups, where are the commercial uses for social networks:
Simultaneous to audience growth, information being added to the Internet will grow from 4.4 billion GB per day in 2016 to 463 billion GB per day in 2025 (IDC estimate). With exploding users and content projected to grow a 100-fold per day, how do you differentiate your messaging to gain, maintain and grow followers, engagement and sales? How do you make sure your content influences and accelerates through the Internet, so you get your “share of eyeballs?”
Social Media Diffusion
Information diffusion is how fast data is moving through a network. It has been studied extensively in social, physical and computational sciences. Research in word of mouth and viral marketing has been documented in business literature. With the emergence of social media, new communication techniques have been explored such as: SMS, weblogs, picture-sharing portals and online communities. The following research considers the variables that effect the diffusion on information on social networks.
Sentiment and Social Media Quantity and Speed
Steiglitz and Xuan conducted research on the effect of emotion on political tweets. This research analyzed 64,432 tweets posted one week before two German state parliament elections. They proved the following hypotheses:
Using supervised learning (regression) the study considered:
Dependent variables
Independent variables
The regression models’ coefficients indicated that for every unit increase in negative words there was a 6% increase in retweets(pg. 238). Likewise, for every unit increase in positive words there was a 4% increase in retweets. An important hypothesis they were not able to prove:
Sentiment and Social Media Predictability
Ashan and Kumari researched 20,000 tweets on the 2016 U.S. presidential election. The analysis considered the impact of sentiment along with the following environmental factors in predicting information diffusion:
Using two different regression approaches, analysis was completed determining the independent variables that provided the best model predictability. As seen below, in each model sentiment content was included and provided a significant increase in predictability.


Including the sentiment content significantly improves the predictability of social media performance and is enhanced with the ability to consider hashtags.
Sentiment and Positivity
Ferrara and Yang conducted a study of 19 million tweets with the following distribution:

Their findings indicated that positive tweets reach a larger audience and are shared more often. As tweet score becomes more positive, the number of retweets, favorites and seconds to first retweet increases at an accelerated rate.

Just how much of a difference does positivity make:
So What? – Words Make a Difference
These are the key findings on sentiment content:
At Yalo, we feel that your words really make a difference. There are many environmental factors that also need to be considered. With these environmental factors we have varied levels of control; however it comes to how we share content we have complete control. Control of what we share and also how we share it! Sentiment analysis from Yalo is the tool to tune content delivery for influencing followers and customers, as well as for analyzing social media traffic that reflects and responds to brand image.
Interested in this fascinating new Yalo marketing-communications and analytics service? Curious how it could be applied towards your business goals? Let’s have a conversation for nuanced understanding.
Insights And News
Insight | 05.04.21
Natural Language Processing and text analysis are AI techniques for isolating, selecting and measuring the effective nature of unstructured information. With these techniques, sentiment analysis is applied for understanding customer feedback (reviews, surveys), analyzing social media traffic, creating website content and shaping marketing campaign messaging.
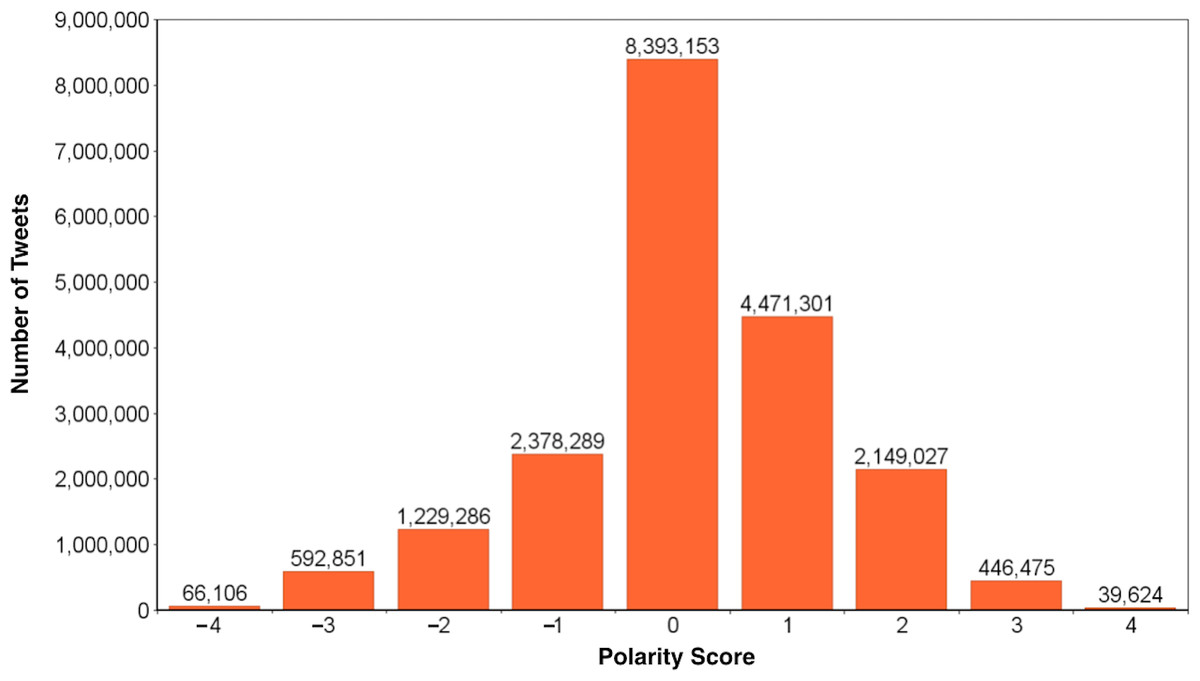
A scored word list is a supervised learning technique for completing sentiment analysis. The scored list or lexicon contains words with scores from most negative to most positive. Numbers assigned depend on the lexicon being used, for example AFINN scores range from -4 to +4. Text is decomposed into its individual words. The individual words are matched against the lexicon, summed and divided by the number of words to get an average score. Lexicons can be developed using surveys and adjusted to address specific domains. This approach can be enhanced with a rules base to address other language features, such as context, multipolarity and negation resulting in a compound calculated score for a piece of text. The power of this approach is in understanding the effect of each word and then being able to adjust the rules.
Using clustering, unsupervised learning can also be used for sentiment analysis. Like any unsupervised technique data is fed into the model, in this case, text – and in real time the model returns the overall results of positive, neutral or negative. To build the module, representative embeddings must be isolated and scored. Clustering is then completed on the data. The relative location of words in a cluster determines their positive or negative value. Then each word is considered for how unique it is in each sentence. This along with the sentiment scores are used to complete sentence scoring.
Some applications of sentiment analysis tools include:
Content Creation – confirming intended sentiment for social media and website content
Customer Feedback – analyzing market sentiment towards products and/or services
Product Review – capturing the most valued product features
Brand Image – monitoring social media by segment for sentiments on brand
Stock Market – real time assessment of investor sentiment on stocks, influencing long/short positions
Regulatory Compliance – identify, extract and understand regulatory, legal and medical documents that traditional data analytics techniques can’t handle
Competitor Intelligence – comparing sentiment on social media against competitors

Sentimental Analysis Tools Value
Sentiment analysis confirms the intent of communications: emails, website content and social media postings. This contributes to the reach, impressions and engagement of these communications. With studies indicating positive emotions increase the speed and reach of social messages, sentiment analysis has significant value. In addition to social media applications, sentiment analysis tools also provide value in tracking customer service feedback and product reviews.
Learn about Yalo’s own Sentiment Analysis services for our clients. Contact us please for any general inquiries, here.
Insights And News
Insight | 04.27.21
Many historical perspectives identify the genesis of Natural Language Processing with Alan Turing’s efforts during World War II cracking the Nazi’s Enigma code machine. By any measure, his Ultra intelligence and Turing machine saved millions of lives and shortened the war by multiple years.

NLP Evolution
After World War II, Turing’s direction involved establishing the foundation of NLP in his article, “Computing Machinery and Intelligence.” This ground-breaking article is viewed as the first treatise on artificial intelligence. He proposed the “Turing test,” (see below) for addressing the question,” can machines think?” He supported his position by rebutting nine arguments against intelligent machines. The nutshell result -thinking machines do not just isolate the words; they identify what the words mean in context.
“A computer would deserve to be called intelligent if it could deceive a human into believing that it was human.” – Alan Turing
NLP Components
Building on this foundation, language translation, language theory, probabilistic and data driven models have yielded what we know of as NLP today. Using NLP, computers dissect, absorb and draw meaning from language in context by:
NLP Applications
It is surprising how many everyday situations benefit from the application of NLP. Some of them include:
NLP and Sentiment Analysis
Natural Language Processing as part of the artificial intelligence discipline is the foundation for sentiment analysis. Both supervised and unsupervised learning techniques can be applied to complete sentiment analysis. The approach being used relies on the input word, sentiment values definition, and the level of control desired in understanding, modifying and acting on the results.
NLP Strengths
Natural Language Processing’s power is derived by its ability to understand and manipulate the human language. This ability delivers exact answers to questions without extraneous information. In addition, NLP can provide structure and sequence to ambiguous information. Yalo utilizes these functions as part of our new Sentiment Analysis services for expanded social media success for our clients.
Insights And News
Insight | 04.12.21

Unsupervised Learning Defined
In unsupervised learning the model works independently discovering patterns and information that were not previously defined. This learning technique works predominantly with unlabeled data (no defined relationship between inputs and outputs). Using this technique affords the opportunity to address more complex processing tasks vs. supervised learning.
Unsupervised Learning Techniques
An important unsupervised learning technique is clustering. Cluster algorithms find groups within the input data. Clustering allows the user to define the number of clusters that should be identified. The number of clusters determines the specificity of each cluster (e.g. the more clusters the more specific the data within a cluster). Unsupervised learning cluster types include:
Clustering techniques include:
Another unsupervised learning technique is association. In this technique, rules are used to establish associations among objects in large data bases. An application of this technique experienced every day is shopping groups based on eCommerce searches and purchases.

Unsupervised Learning Applications
Customer Segmentation – understanding customer groups for building business strategies and marketing campaigns
Genetics – grouping DNA patterns to study evolutionary biology.
Predictive Maintenance – detecting defective mechanical parts
Dimensionality Reduction – problem simplification by reducing random variables resulting in better data visualization
Ecology – comparison of audio recording of regions for comparison of species population for biodiversity
Delivery Routes – optimize delivery efficiency by determining the optimal number of regional locations and efficient truck routes.
Crime Zones – crime data by specific location including area and category for defining crime concentration locations within a city.
System Alert Management – operations alert messages from IT system components prioritized based on mean time to repair, downstream impact and failure predictions.
Unsupervised Learning Advantages & Disadvantages
Plus
Minus
One Application Plus that Yalo is investing in for our clients is our new sentiment analysis service – capable of several insightful deliverables that can boost your marketing & branding campaign successes. Contact us today to learn how our new tools powered by AI can be a boon for your 21st century business.
Insights And News
Insight | 03.24.21

AI has two approaches in programming intelligent machines: supervised learning and unsupervised learning. Supervised learning requires data with defined input/output relationships (labeled data). The comparison being taught by a supervisor or teacher. The resulting supervised learning algorithm uses the learning to predict outcomes from new input data. Over time the model must be maintained to ensure that the labeled data is both current and complete.
Unsupervised machine learning requires no supervision. Using this approach, the model works on its own to infer information from unlabeled data. There is no information on the outputs, the model identifies patterns from the data. This approach supports more complex processing tasks when compared to supervised learning. Unsupervised learning can be more unpredictable when compared to other learning methods.

Supervised Learning Advantages
Supervised learning takes advantage of collecting/developing data from existing experiences. This provides an approach for optimizing a model’s performance. Supervised learning is valuable in addressing computational problems.
Unsupervised Learning Advantages
Unsupervised learning is adept at discovering unknown patterns in data. The identification of the patterns occurs in real-time and labeling is completed in the presence of the learners. Using unlabeled data, unsupervised learning does not require the data labeling effort.
Supervised Learning in Action
Supervised learning trains the machine to complete a task. Suppose you wanted to predict how many games a pitcher will win in an upcoming season using prior year performance. The process requires the collection of a data set of pitching performance by pitcher. Example data could be:

These inputs for a particular pitcher would be collected and the model determine the output, number of games won.
The labeled data defines a training data set used as an input for training the model. The model may conclude that more strikes and less walks are desirable. Similarly, more ground balls and fewer flyballs. The learning process takes this training data, isolates attributes and develops an algorithm(s) which become the model.
Unsupervised Learning in Action
Unsupervised learning uses data with no labels. An example for unsupervised learning would be if you went to a baseball game and had no idea how the game is played, you would watch and make observations to develop an understanding of how the game is played. You would notice
You would be learning baseball without any assistance. The learning would have occurred by identifying patterns that were not previously known.
Summary – Supervised vs. Unsupervised Learning
The learning methods differ on how data is used. Input data is labeled for supervised learning and unlabeled for unsupervised learning. Supervised learning uses the output data to learn and outputs to new inputs. Unsupervised learning does not use output data. Supervised learning is a simpler method with learning performed offline versus unsupervised learning being computationally more complex and occurring in real time.
The major unsupervised learning drawback is that without labels, complete information on data grouping and output data is not available. Supervised learning requires the classification of the data. Supervised learning is considered a trusted process with accurate results, whereas, unsupervised learning in more unpredictable.
Both of these processes and more contribute to the fascinating power of artificial intelligence. In the workplace, Yalo is using our new sentiment analysis services to leverage AI for social media monitoring and actionable insights for our clients. Request a demo in order to understand how these amazing tools can help to build and boost your brand.
Insights And News


{kind=link}